


Traitement de données massives
La majorité des traitements de masse de données volumineuses sont réalisés au moyen de shells sous UNIX qui font appel à des procédures telles que d’autre shells ou des programmes exécutables écrits dans différents langages (essentiellement F90 ou C), ou encore a des procédures écrites en IDL.
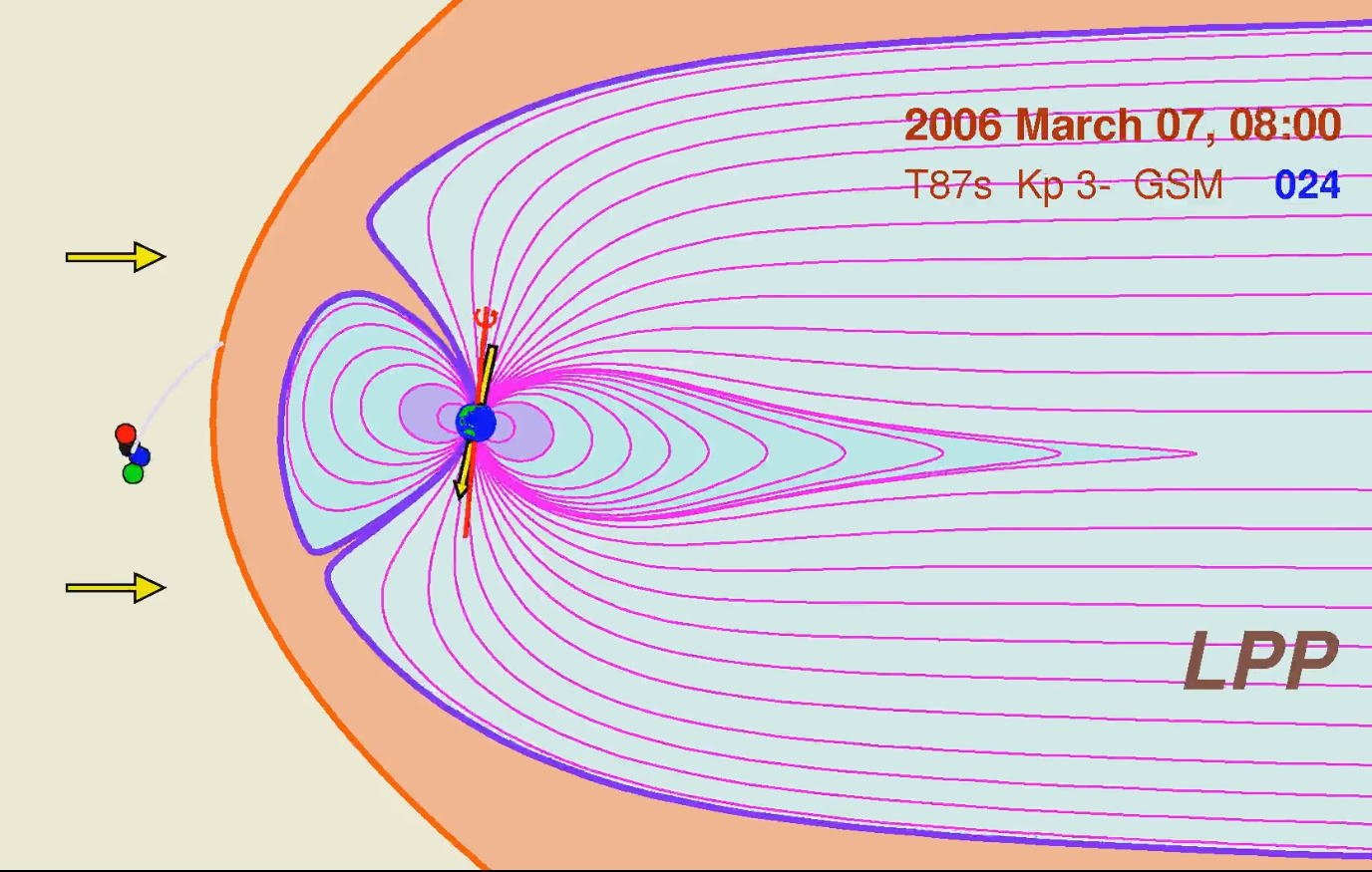
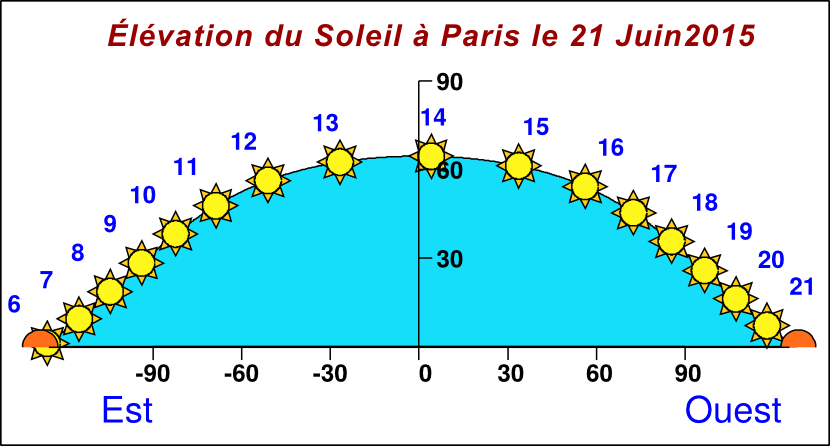
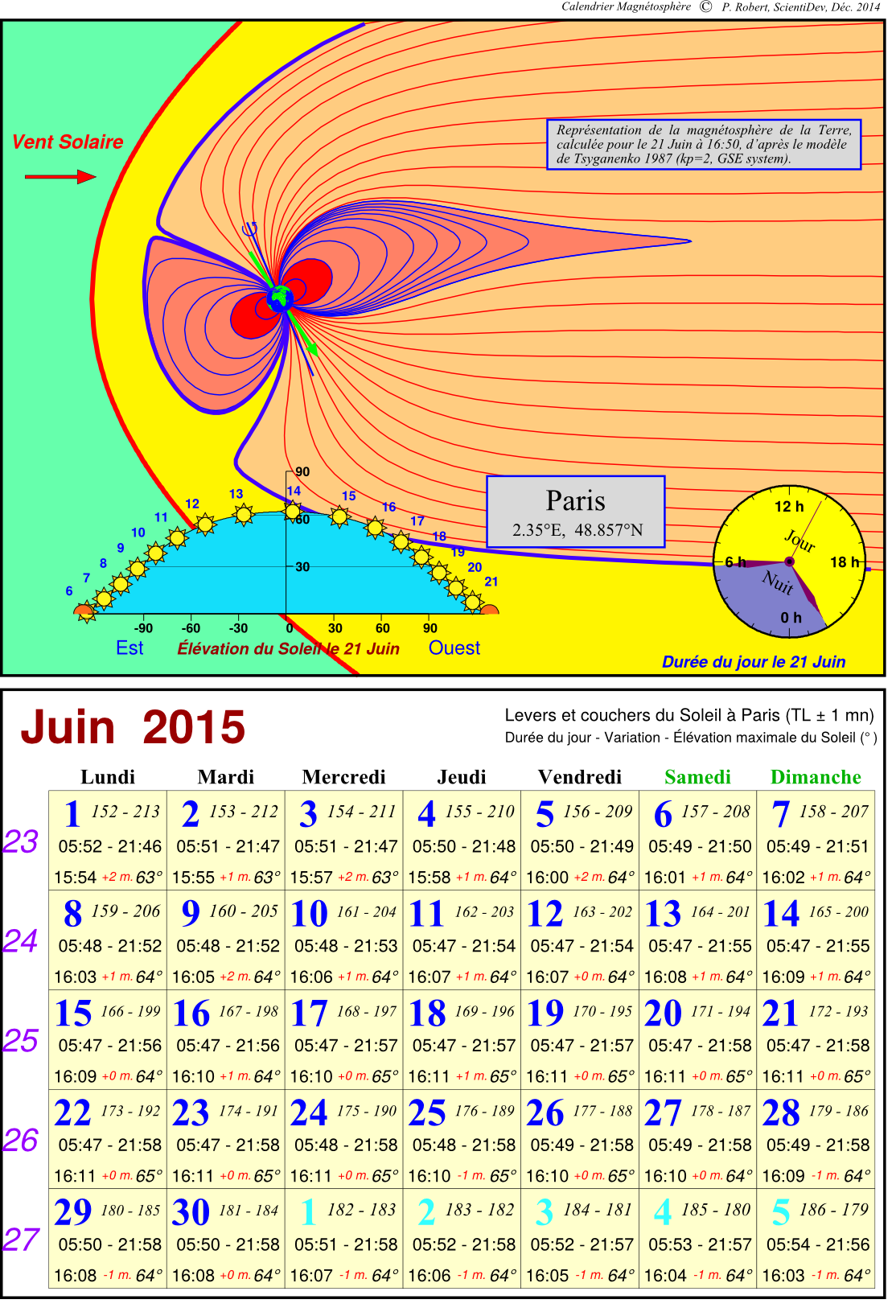
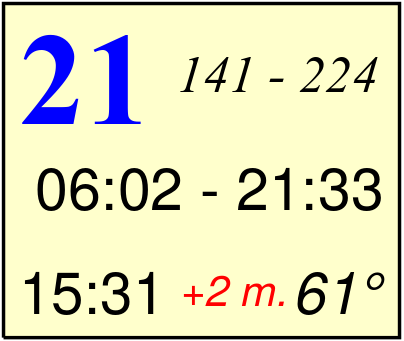
Les exemples de visualisations disponibles dans la page « Base de données» ont été ainsi produites.
Certains codes d’exploitation sont aussi disponibles sous
Windows.
Faites-nous part de vos besoins !
nous étudions toute proposition gratuitement...